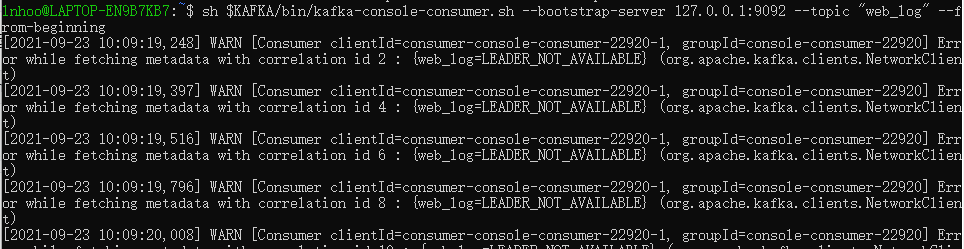
service Twitter { // A method definition looks like C code. It has a return type, arguments, // and optionally a list of exceptions that it may throw. Note that argument // lists and exception list are specified using the exact same syntax as // field lists in structs. void ping(), // bool postTweet(1:Tweet tweet) throws (1:TwitterUnavailable unavailable), // TweetSearchResult searchTweets(1:string query); //
// The 'oneway' modifier indicates that the client only makes a request and // does not wait for any response at all. Oneway methods MUST be void. oneway void zip() // }
2 Typedef
相当于 C++ 中的 typedef,可以为底层数据类型起一个别名。
1 2
typedef i32 MyInteger typedef Tweet ReTweet
3 Enum
概念上和 C 语言中的枚举类型相似,可以定义一组常量的集合。默认值从0开始,也可以自己指定,接受10进制和16进制形式的数值。
service Twitter { // A method definition looks like C code. It has a return type, arguments, // and optionally a list of exceptions that it may throw. Note that argument // lists and exception list are specified using the exact same syntax as // field lists in structs. void ping(), // bool postTweet(1:Tweet tweet) throws (1:TwitterUnavailable unavailable), // TweetSearchResult searchTweets(1:string query); //
// The 'oneway' modifier indicates that the client only makes a request and // does not wait for any response at all. Oneway methods MUST be void. oneway void zip() // }